|
I am a MS student in Electrical and Computer Engineering (ECE) at the University of California, San Diego (UCSD). Previously, I received my B.Eng. in Automation Engineering from Xi’an Jiaotong University (XJTU). I also spent a wonderful time as an exchange student at CUHK. My research interests lie in Video Understanding and Generative Modeling. |

|
|
|
|
|

|
Liuzhuozheng Li, Yue Gong, Shanyuan Liu, Zanyi Wang, Dengyang Jiang, Liebucha Wu, Bo Cheng, YuhangMa, Dawei Leng, Yuhui Yin Conference on Computer Vision and Pattern Recognition (CVPR), 2026 code / arXiv An End-to-End Virtual Try-on model that directly fits the target garment onto the person image. |
|
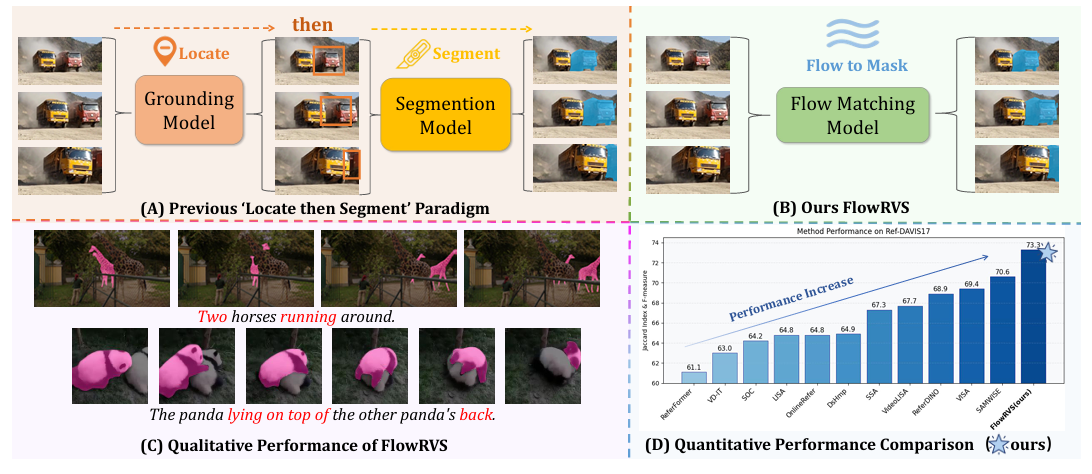
Zanyi Wang, Dengyang Jiang, Liuzhuozheng Li, Sizhe Dang, Chengzu Li, Harry Yang, Guang Dai, Mengmeng Wang, Jingdong Wang International Conference on Learning Representations (ICLR), 2026 code / arXiv / 机器之心 Reformulated RVOS as learning a continuous, text-conditioned flow that deforms a video's content into its target mask. |
|
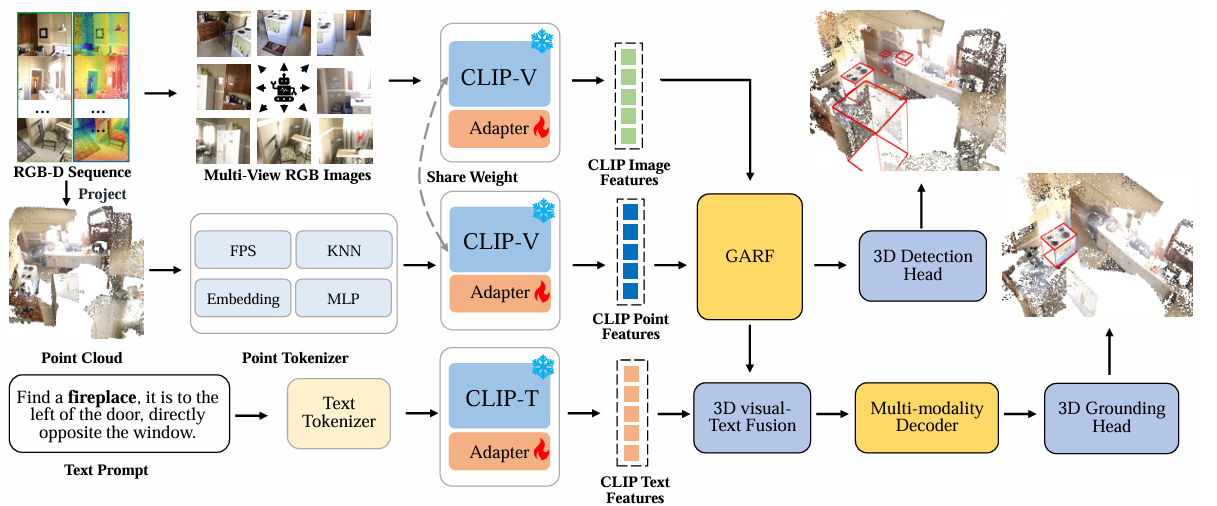
Fan Li, Zanyi Wang*, Zeyi Huang, Guang Dai, Jingdong Wang, Mengmeng Wang ACM International Conference on Multimedia (ACM MM), 2025 arXiv Developed a unified framework leveraging CLIP’s ViT encoder for efficient tri-modal 3D visual grounding. |
|
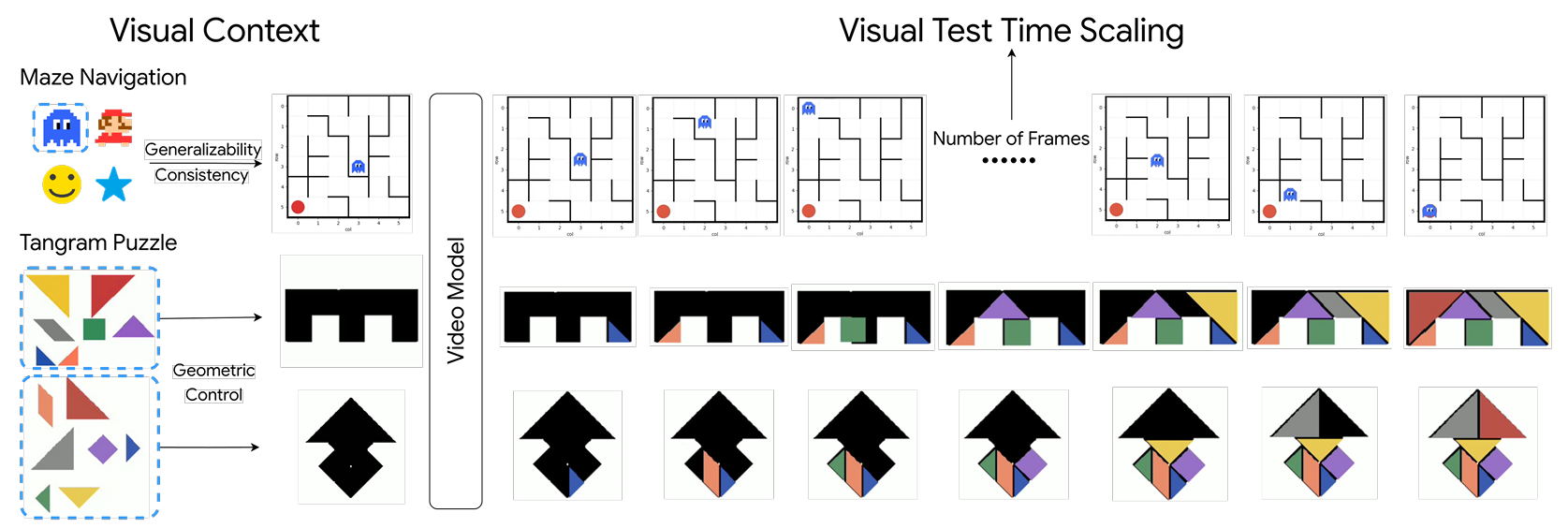
Chengzu Li, Zanyi Wang*, Jiaang Li, Yi Xu, Han Zhou, Huanyu Zhang, Ruichuan An, Dengyang Jiang, Zhaochong An, Ivan Vulić, Serge Belongie, Anna Korhonen Preprint, 2026 arXiv Exploring how visual context enhances video reasoning capabilities. |

|
Dengyang Jiang, Dongyang Liu, Zanyi Wang, Qilong Wu, Liuzhuozheng Li, Hengzhuang Li, Xin Jin, David Liu, Zhen Li, Bo Zhang, Mengmeng Wang, Steven Hoi, Peng Gao, Harry Yang Preprint, 2026 code / arXiv Showing that DMD and RL can be trained simultaneously, with RL enabling the student model to surpass the teacher and DMD loss regularizing RL to prevent reward hacking. |
|
Design and source code from Jon Barron's website. |